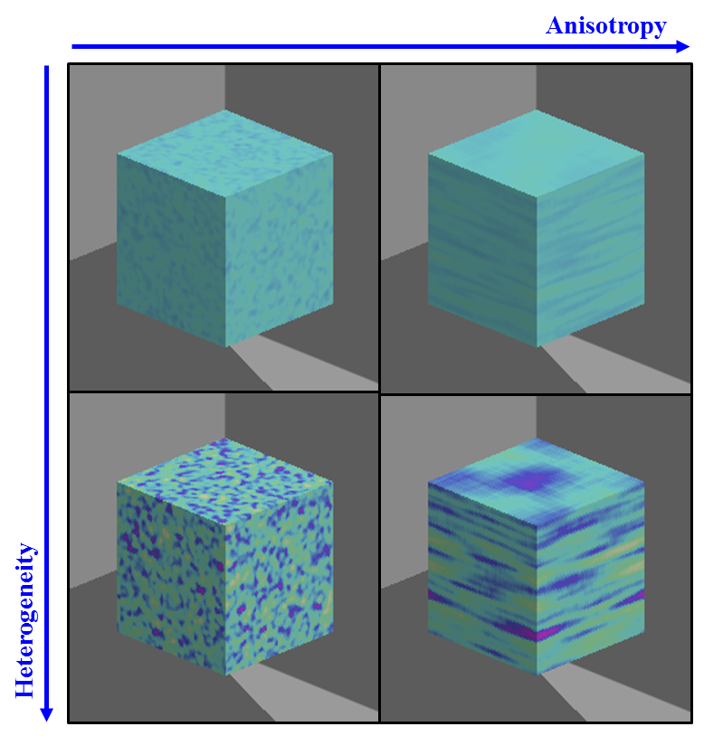
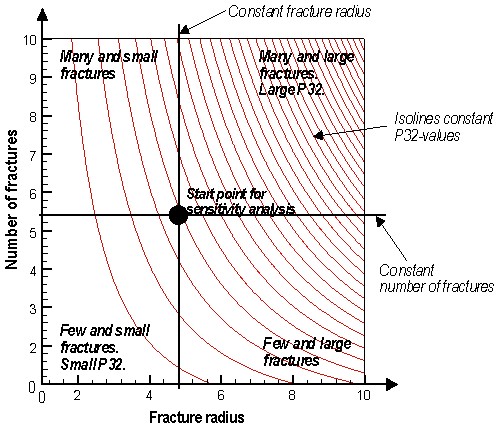
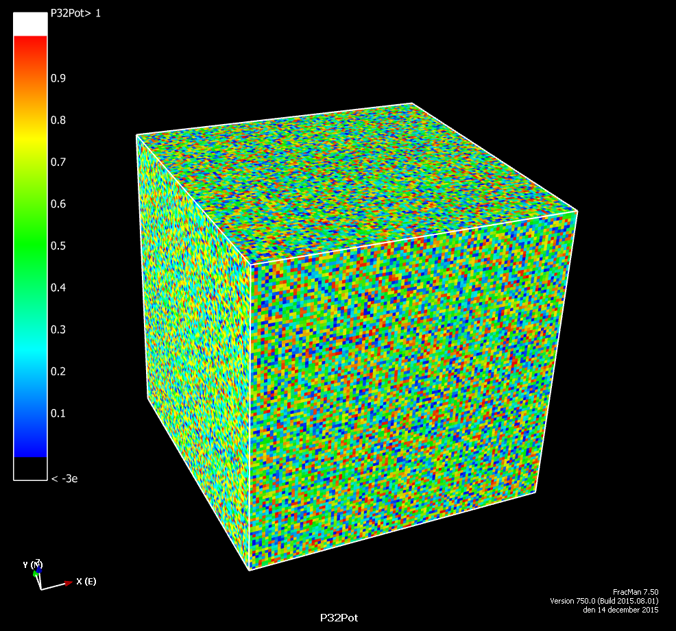
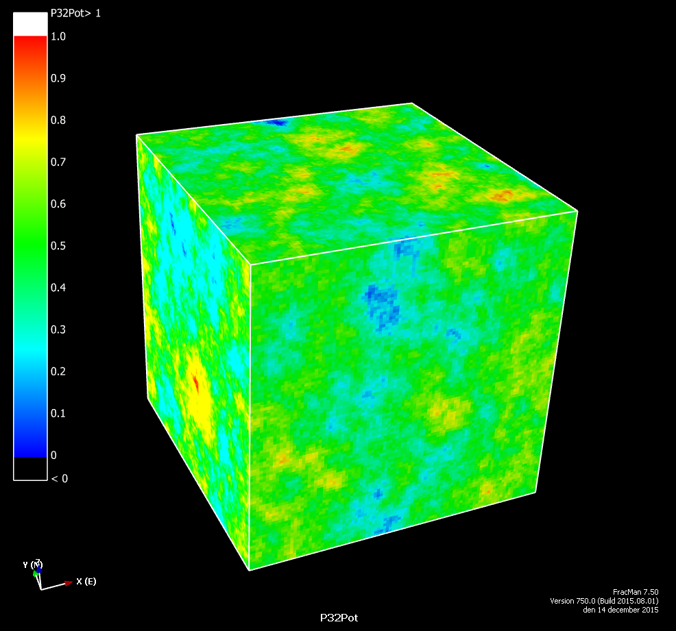
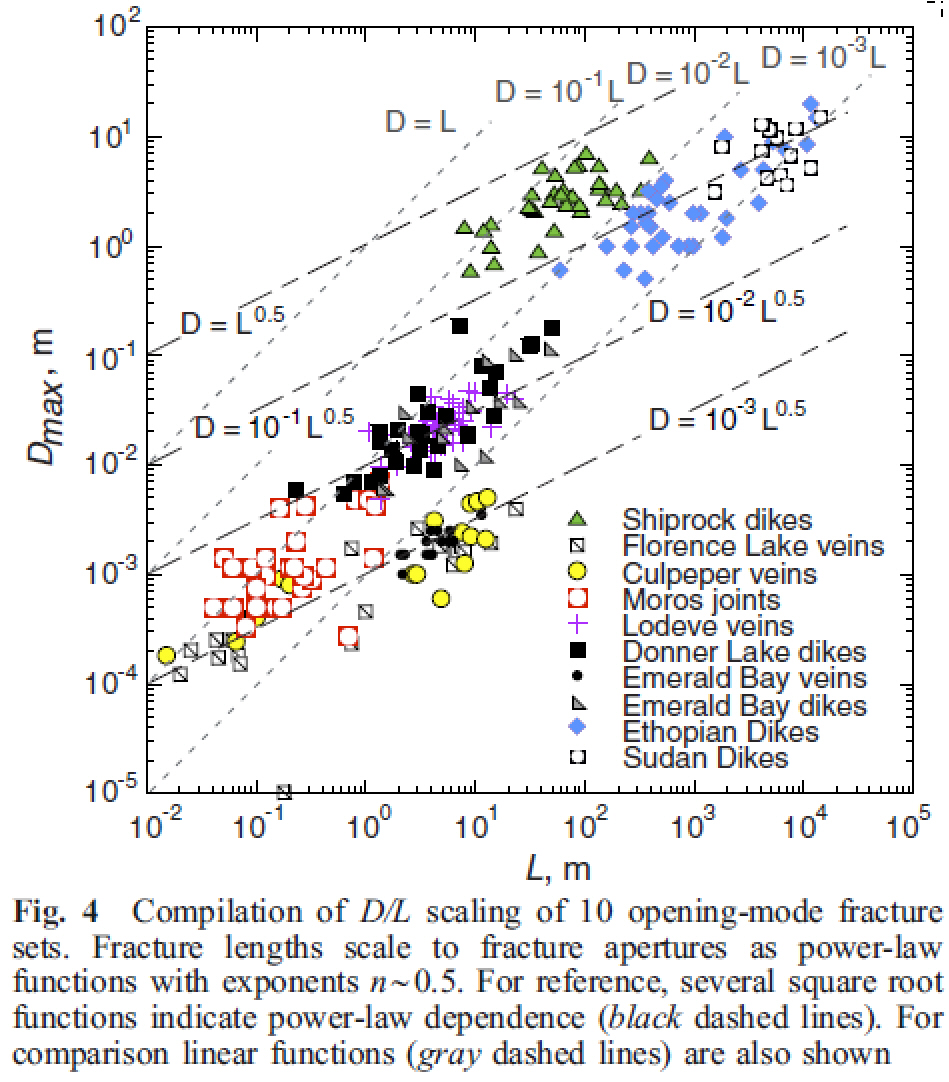
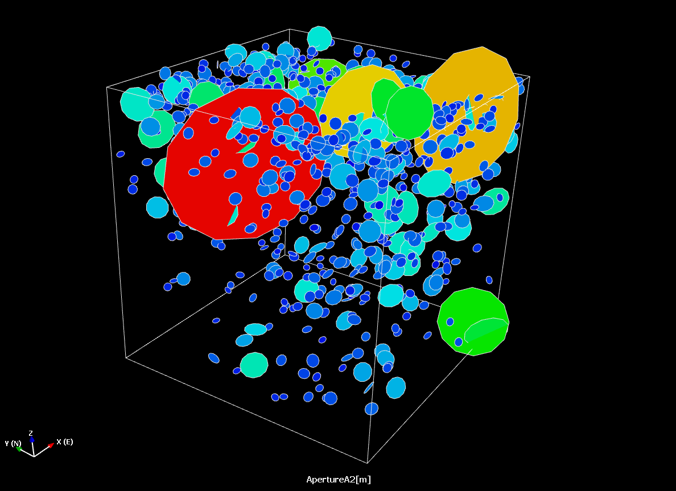
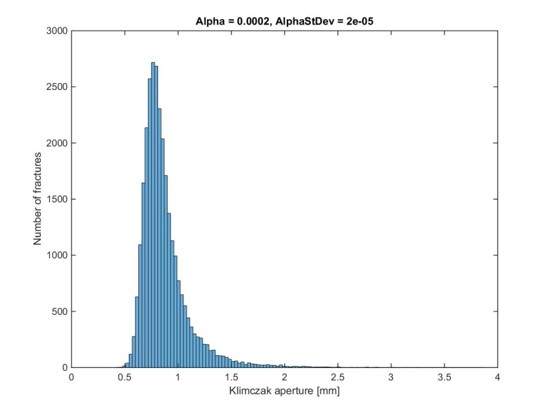
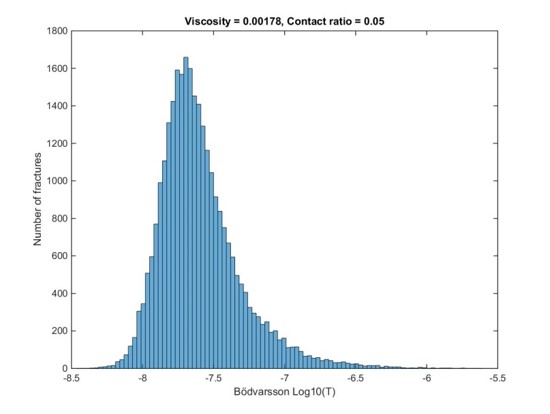
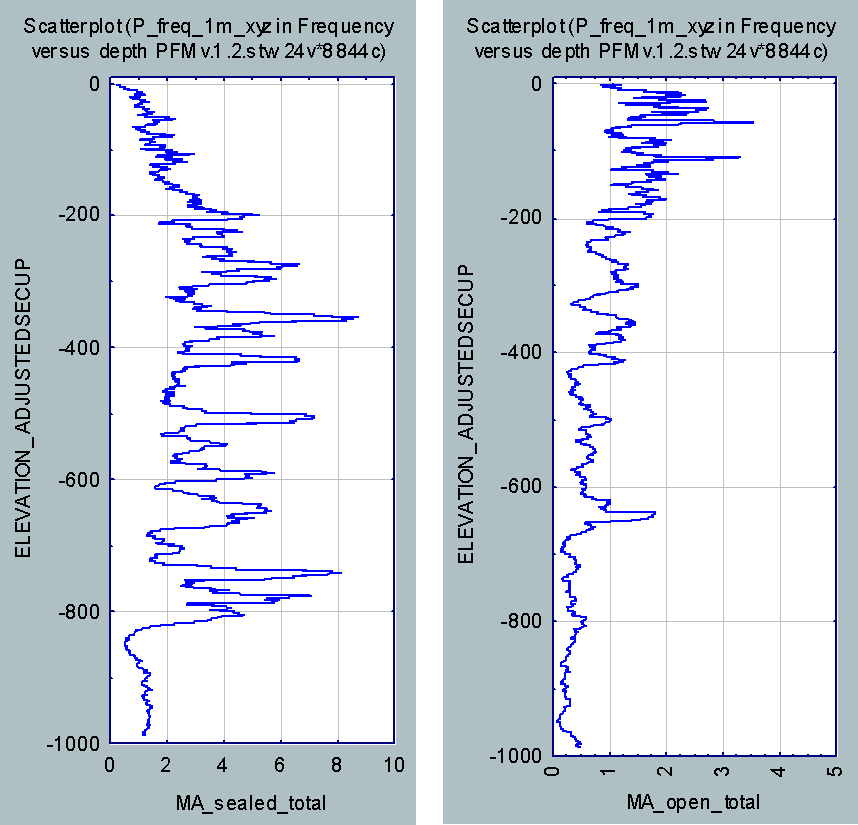
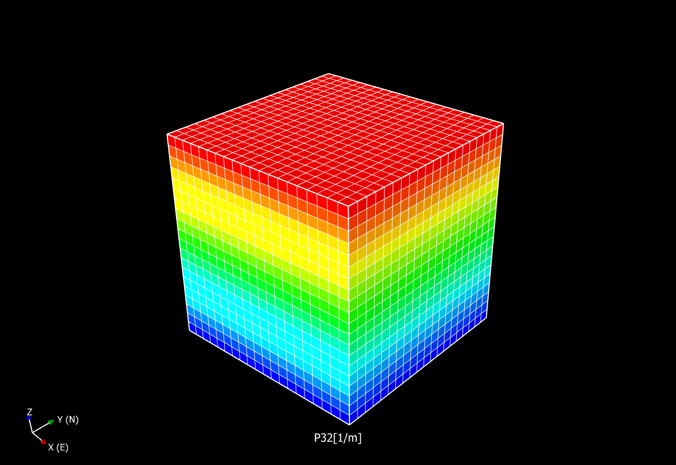
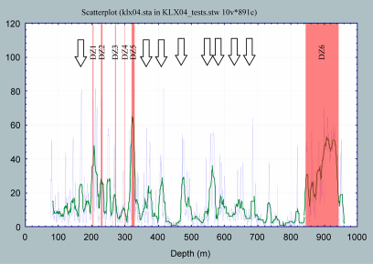
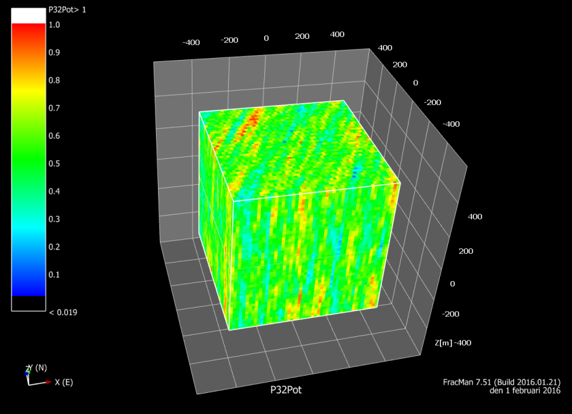
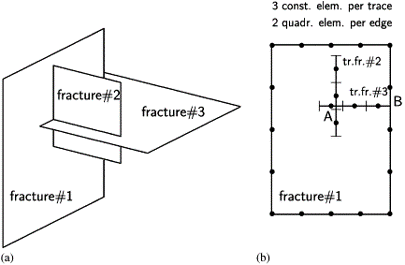
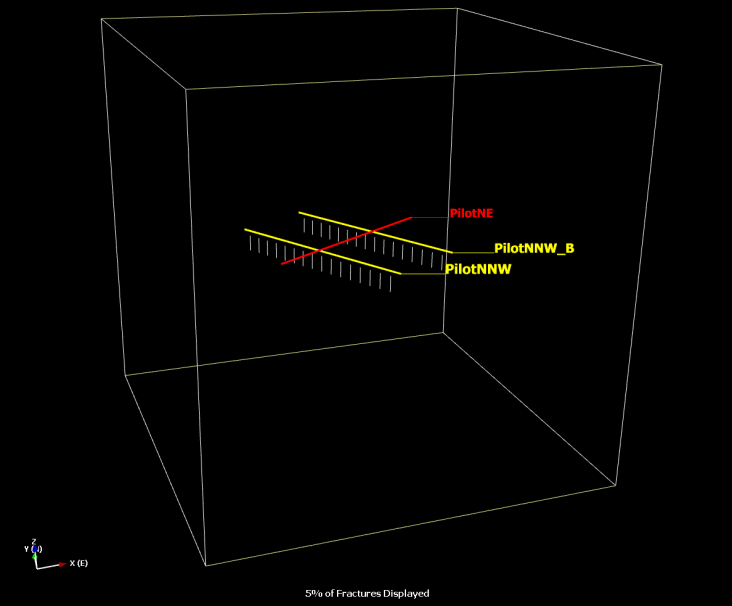
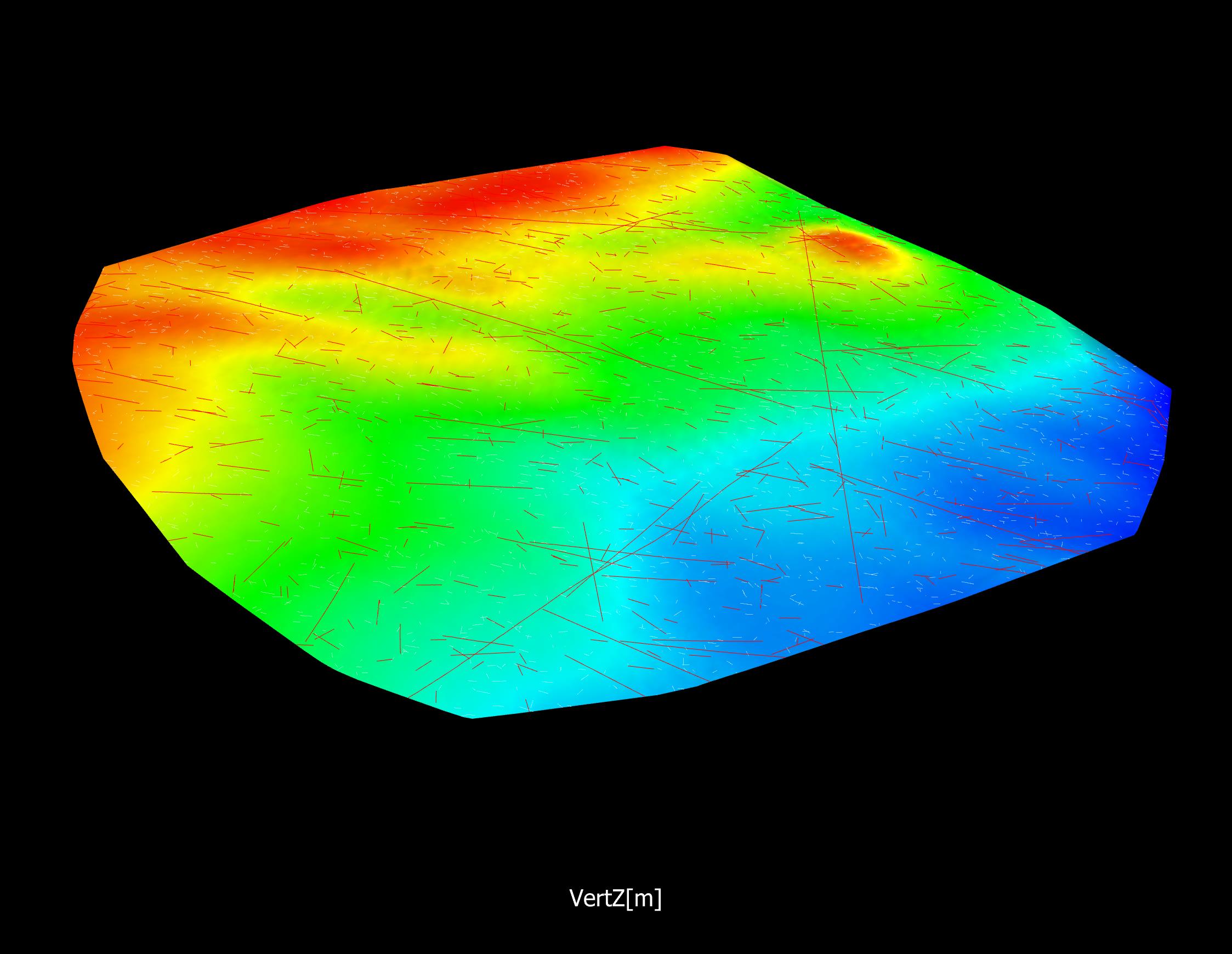
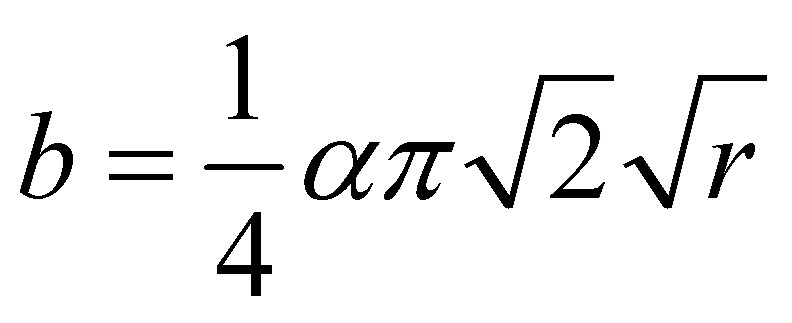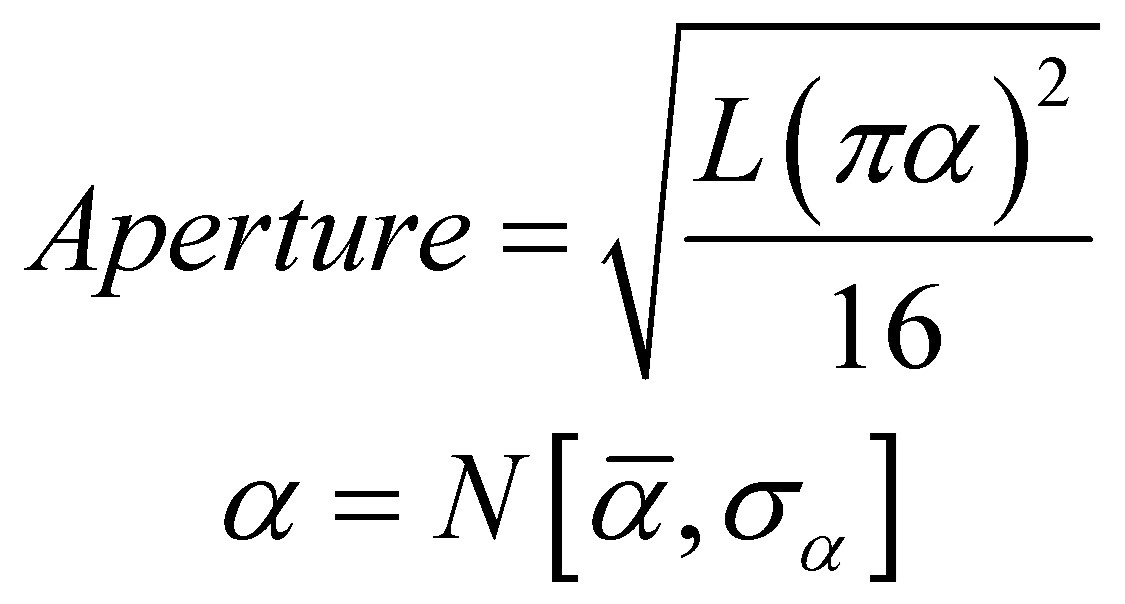Is it possible to test if a model is correct? Ask yourselves, first: What does “correct” mean? What does “model” mean? The latter can be debated for ages with no success, everyone I have encountered in the business has a perfectly clear view of what a model is, and they all differ. Most of them are right though…For an exposé, have a look at the excellent paper on the issue by Nordstrom.
How many papers have you seen in which “models” are “validated” against real “data”? Can a model even be “validated”? The clear and easy answer is simply no! Karl Popper argued that the induction approach to science, which emanated from the Renaissance era, should be repudiated. Instead Popper argued for “falsification”. With this is meant that a model can be proven wrong, but never proven to be right. So if we believe in Popper, our task is to try to prove a model wrong. If we fail, after hard work, then probably our model is not very wrong, at least for the moment.
So how do we test if a model is wrong? Well, that is actually fairly easy. If it fails to predict what we know is right, within reasonable bounds, then it is simply wrong! But how do we know what is right? Certainly not by comparing to samples from the real world with all their biases, intrinsic variability, resolution issues, instrumental imprecision, human errors, etc.
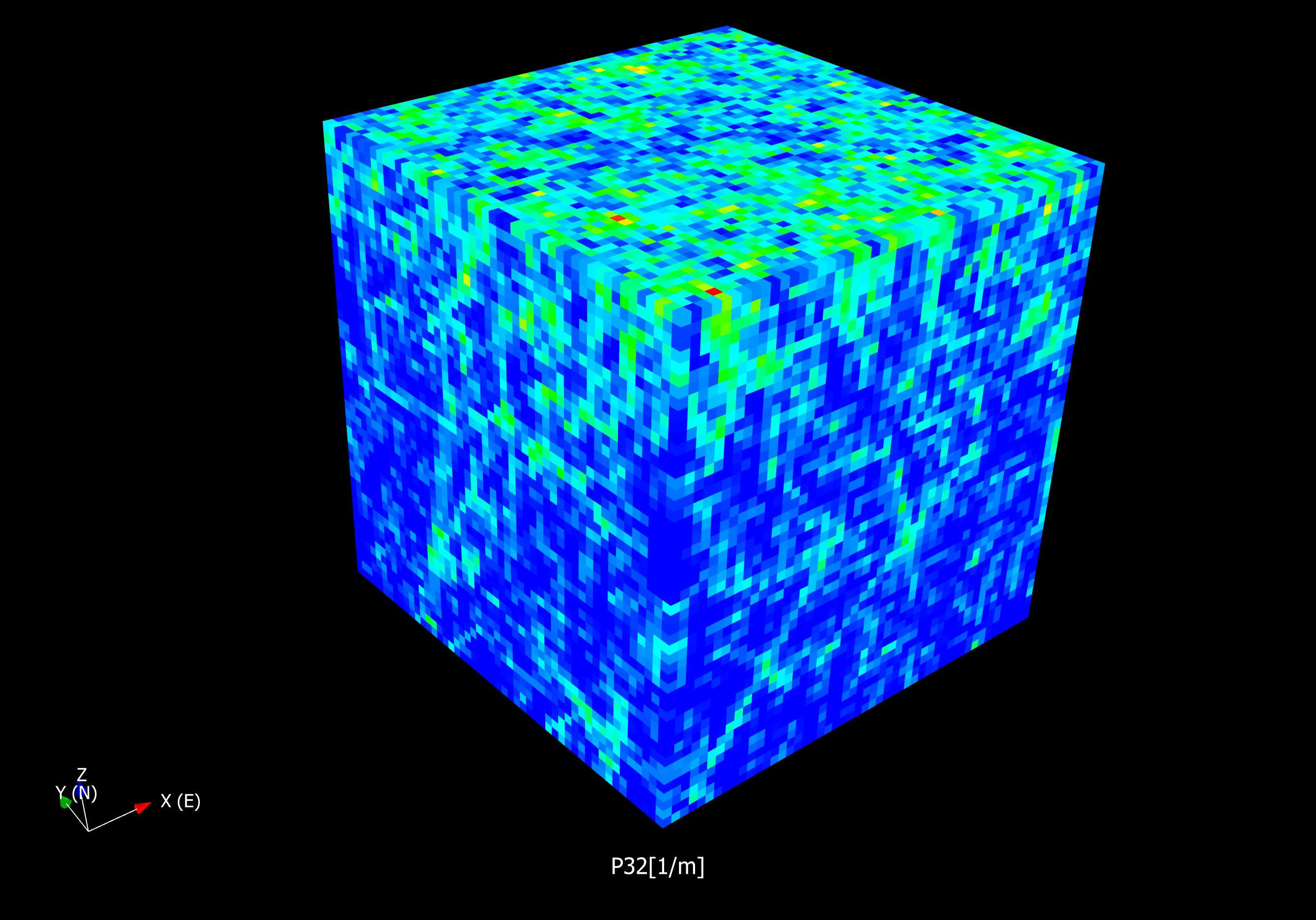
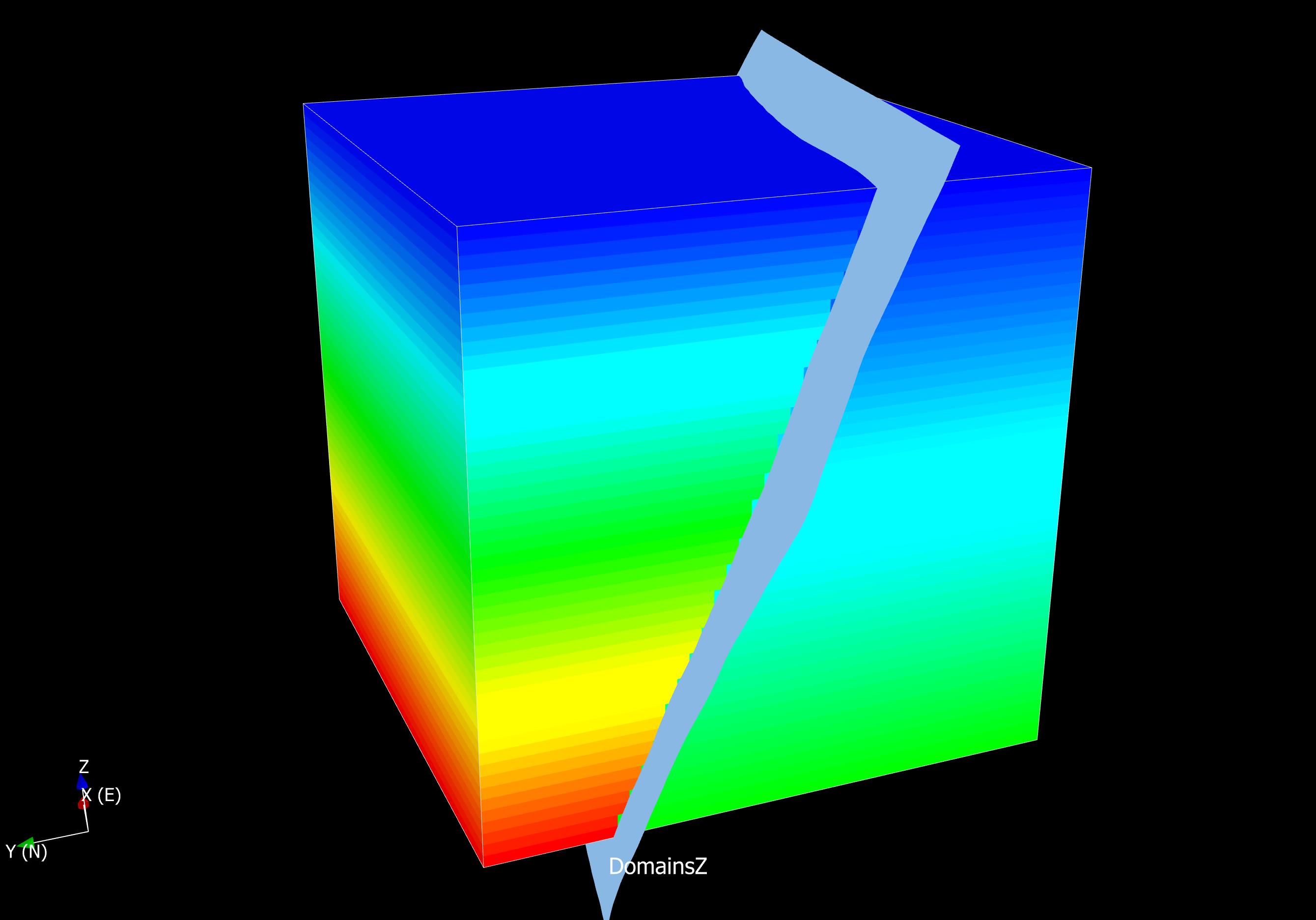
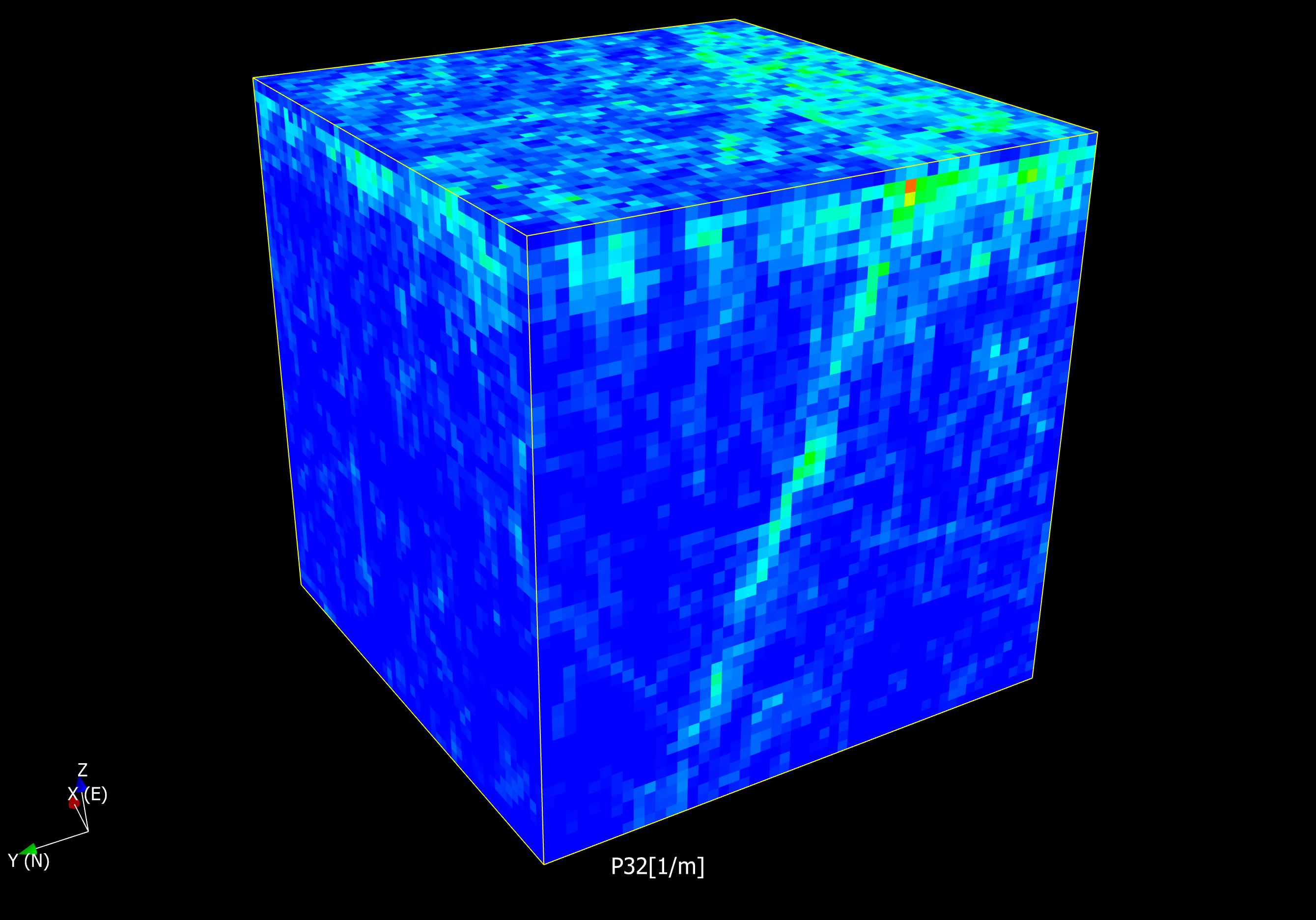
The only way to know what is right, without any doubt and full control over all variability, is to construct the reality against which we test our model. If we fail to replicate what we know is right, we need to iterate the modelling procedure, reassess our assumptions, tweek parameters and so on until we succeed. Thereafter we might apply our codes to real data and hope that our model is not too wrong. Given, of course, that our artificial data is sufficiently close to the reality we aim our modelling efforts towards.